The documentation you are viewing is for Dapr v1.10 which is an older version of Dapr. For up-to-date documentation, see the latest version.
Actors overview
The actor pattern describes actors as the lowest-level “unit of computation”. In other words, you write your code in a self-contained unit (called an actor) that receives messages and processes them one at a time, without any kind of concurrency or threading.
While your code processes a message, it can send one or more messages to other actors, or create new actors. An underlying runtime manages how, when and where each actor runs, and also routes messages between actors.
A large number of actors can execute simultaneously, and actors execute independently from each other.
Actors in Dapr
Dapr includes a runtime that specifically implements the Virtual Actor pattern. With Dapr’s implementation, you write your Dapr actors according to the actor model, and Dapr leverages the scalability and reliability guarantees that the underlying platform provides.
Every actor is defined as an instance of an actor type, identical to the way an object is an instance of a class. For example, there may be an actor type that implements the functionality of a calculator and there could be many actors of that type that are distributed on various nodes across a cluster. Each such actor is uniquely identified by an actor ID.
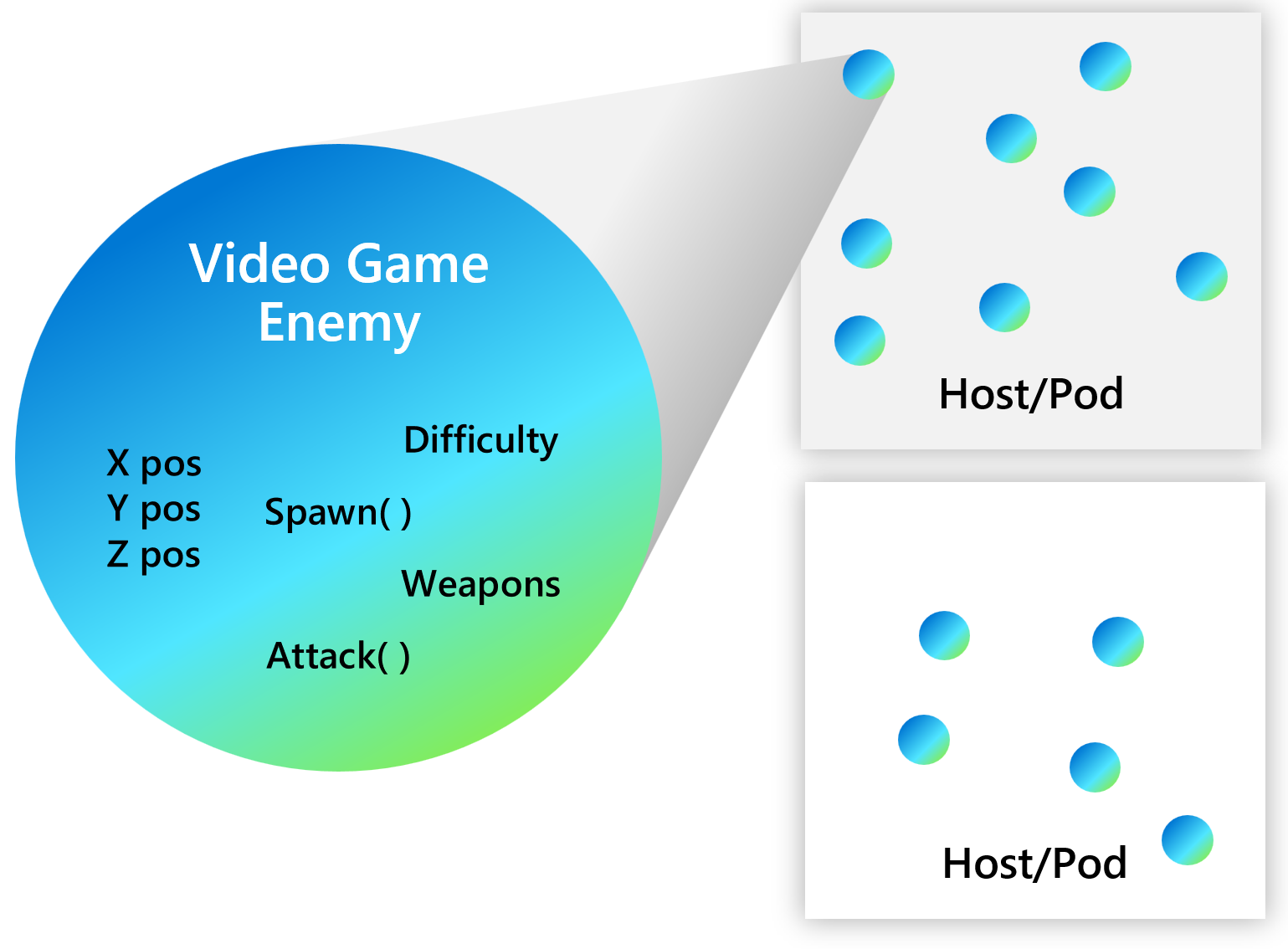
Dapr actors vs. Dapr Workflow
Dapr actors builds on the state management and service invocation APIs to create stateful, long running objects with identity. Dapr Workflow and Dapr Actors are related, with workflows building on actors to provide a higher level of abstraction to orchestrate a set of actors, implementing common workflow patterns and managing the lifecycle of actors on your behalf.
Dapr actors are designed to provide a way to encapsulate state and behavior within a distributed system. An actor can be activated on demand by a client application. When an actor is activated, it is assigned a unique identity, which allows it to maintain its state across multiple invocations. This makes actors useful for building stateful, scalable, and fault-tolerant distributed applications.
On the other hand, Dapr Workflow provides a way to define and orchestrate complex workflows that involve multiple services and components within a distributed system. Workflows allow you to define a sequence of steps or tasks that need to be executed in a specific order, and can be used to implement business processes, event-driven workflows, and other similar scenarios.
As mentioned above, Dapr Workflow builds on Dapr Actors managing their activation and lifecycle.
When to use Dapr actors
As with any other technology decision, you should decide whether to use actors based on the problem you’re trying to solve. For example, if you were building a chat application, you might use Dapr actors to implement the chat rooms and the individual chat sessions between users, as each chat session needs to maintain its own state and be scalable and fault-tolerant.
Generally speaking, consider the actor pattern to model your problem or scenario if:
- Your problem space involves a large number (thousands or more) of small, independent, and isolated units of state and logic.
- You want to work with single-threaded objects that do not require significant interaction from external components, including querying state across a set of actors.
- Your actor instances won’t block callers with unpredictable delays by issuing I/O operations.
When to use Dapr Workflow
You would use Dapr Workflow when you need to define and orchestrate complex workflows that involve multiple services and components. For example, using the chat application example earlier, you might use Dapr Workflows to define the overall workflow of the application, such as how new users are registered, how messages are sent and received, and how the application handles errors and exceptions.
Learn more about Dapr Workflow and how to use workflows in your application.
Features
Actor lifetime
Since Dapr actors are virtual, they do not need to be explicitly created or destroyed. The Dapr actor runtime:
- Automatically activates an actor once it receives an initial request for that actor ID.
- Garbage-collects the in-memory object of unused actors.
- Maintains knowledge of the actor’s existence in case it’s reactivated later.
An actor’s state outlives the object’s lifetime, as state is stored in the configured state provider for Dapr runtime.
Learn more about actor lifetimes.
Distribution and failover
To provide scalability and reliability, actors instances are throughout the cluster and Dapr distributes actor instances throughout the cluster and automatically migrates them to healthy nodes.
Learn more about Dapr actor placement.
Actor communication
You can invoke actor methods by calling them over HTTP, as shown in the general example below.
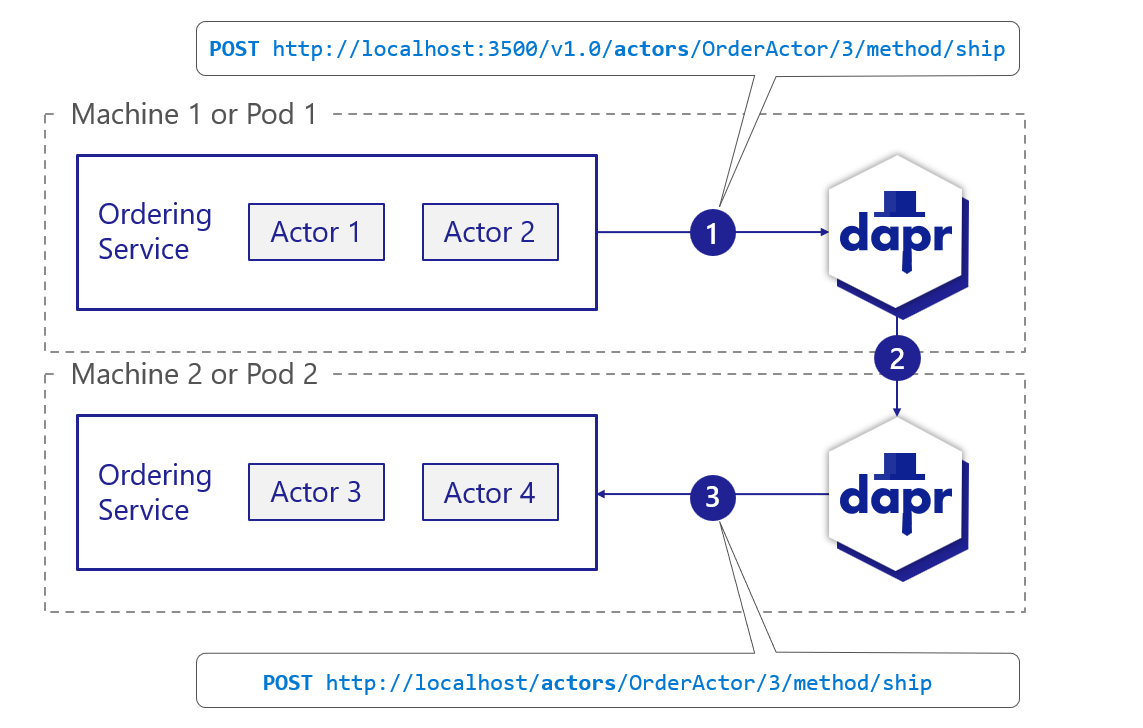
- The service calls the actor API on the sidecar.
- With the cached partitioning information from the placement service, the sidecar determines which actor service instance will host actor ID 3. The call is forwarded to the appropriate sidecar.
- The sidecar instance in pod 2 calls the service instance to invoke the actor and execute the actor method.
Learn more about calling actor methods.
Concurrency
The Dapr actor runtime provides a simple turn-based access model for accessing actor methods. Turn-based access greatly simplifies concurrent systems as there is no need for synchronization mechanisms for data access.
Actor timers and reminders
Actors can schedule periodic work on themselves by registering either timers or reminders.
The functionality of timers and reminders is very similar. The main difference is that Dapr actor runtime is not retaining any information about timers after deactivation, while persisting the information about reminders using Dapr actor state provider.
This distinction allows users to trade off between light-weight but stateless timers vs. more resource-demanding but stateful reminders.
- Learn more about actor timers.
- Learn more about actor reminders.
- Learn more about timer and reminder error handling and failover.
Next steps
Actors features and concepts >>Related links
- Actors API reference
- Refer to the Dapr SDK documentation and examples.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.